OpenAI’s 2025 lineup is bigger and more unified than ever. GPT-5 (the default ChatGPT model) introduces a real-time router that decides when to answer quickly and when to “think” longer for difficult problems. GPT-5 Pro, GPT-4o, and o3 remain available for specialized or legacy use cases.
This guide compares the models across benchmarks, coding, mathematics, multimodal reasoning, agents & tool use, pricing, ROI, and safety so you can choose the right tool with confidence.
Let’s start exploring the following topics.
Overview of OpenAI’s 2025 Model Lineup & Unified Architecture
OpenAI’s 2025 release centers on GPT-5 and a router that inspects each request (complexity, tool needs, and intent) and then chooses among modes:
GPT-5 (Standard): General-purpose model that automatically switches between fast and deep-reasoning modes. Default for ChatGPT.
GPT-5 “Thinking” Mode: Built-in extended-reasoning path for complex tasks; invoked automatically or on demand.
GPT-5 Pro: Maximum-performance variant (Pro/Team/Enterprise) for sustained deep reasoning, tight instruction following, and the hardest open-ended work.
GPT-5 mini / nano: Lightweight fallbacks for fast responses or when hitting usage limits; great for high-volume and simple tasks.
ChatGPT Agent: An orchestrated agent that coordinates multiple tools, files, and connectors (e.g., Drive, SharePoint, GitHub) to complete multi-step workflows.
Why it matters: Instead of manually picking a model, you type your question and the system’s router chooses an appropriate strategy, speed when it’s easy, depth when it’s hard.
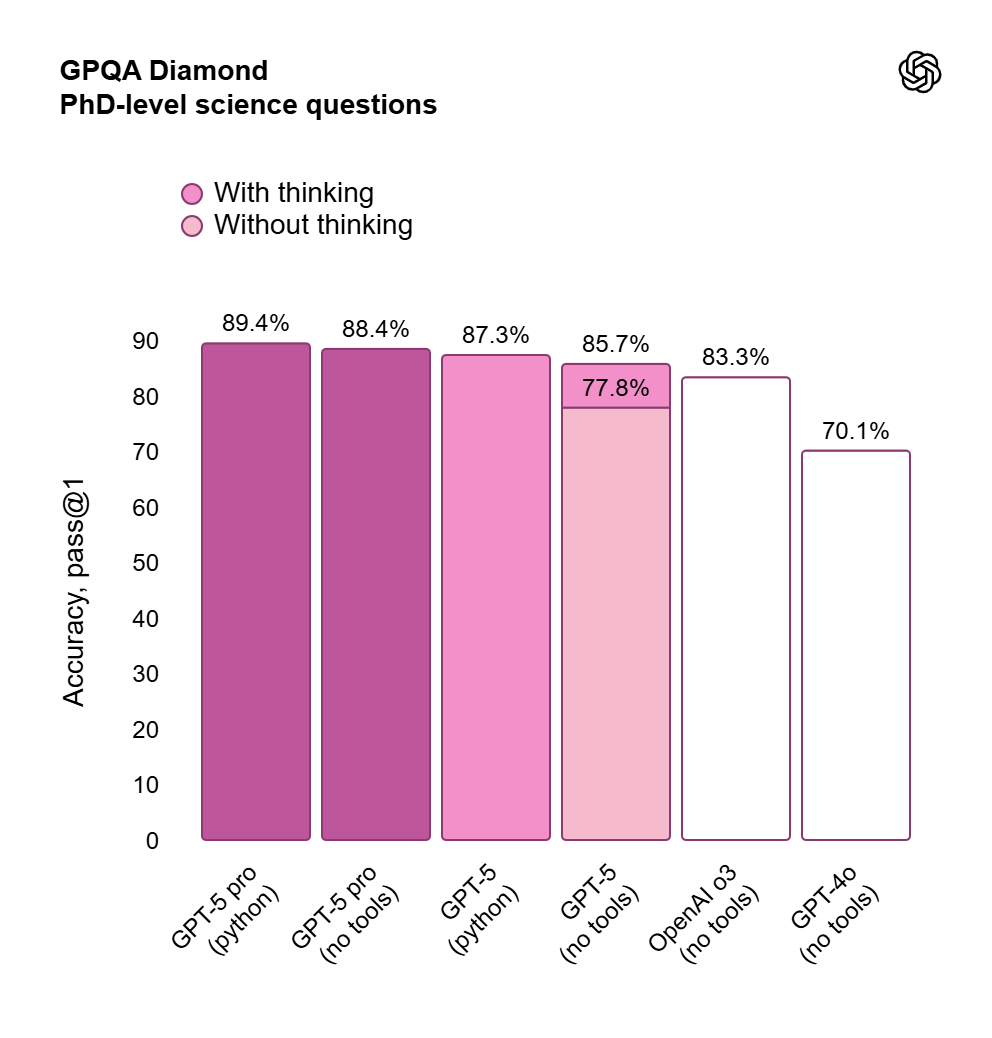
What GPQA measures:GPQA Diamond tests graduate-level science knowledge across physics, biology, chemistry, and related subfields. The questions are intentionally tough and resistant to memorization.
ChatGPT 5 and GPT-5 Pro dominate this benchmark: GPT-5 Pro (with Python) scores 89.4 %, GPT-5 (with Python) 87.3 %, o3 83.3 %, and GPT-4o 70.1 %. The GPT-5 thinking mode makes a big difference, accuracy jumps from 77.8 % to 85.7 % when activated.
How the models compare:
GPT-5 Pro generally tops the chart on complex science questions, especially with Python for computation and verification.
GPT-5 (Standard) narrows the gap when Thinking Mode is active, making it surprisingly capable for day-to-day scientific queries without a Pro plan.
o3 remains a solid legacy baseline for reasoning (especially math), but GPT-5 models typically lead on breadth and consistency.
GPT-4o continues to be a strong multimodal generalist but trails GPT-5 on difficult science reasoning.
Key Takeaway: If you routinely tackle graduate-level science or need the fewest errors on tough problems, GPT-5 Pro is the safe choice; otherwise, GPT-5 with Thinking is an excellent value.
Impact of GPT-5 “Thinking” Mode on Scientific Reasoning
GPT-5’s Thinking Mode adds a multi-step chain-of-thought execution (in the background) with better use of tools (e.g., Python) for verification. Expect jumps in accuracy on:
Derivations and proofs that require many steps.
Data interpretation (tables, charts, experimental results).
Cross-disciplinary synthesis, e.g., combining biology with statistics.
In practice: Thinking Mode narrows the gap with GPT-5 Pro for many users, especially students, analysts, and researchers, while Pro still pushes the frontier for edge cases and high-stakes work.
Software Engineering & Coding Benchmarks
LiveCodeBench / SWE-bench Verified: Where GPT-5 Pulls Ahead
On real-world coding tasks (bug fixes, feature additions, tests), GPT-5 with Thinking Mode scores markedly higher than its fast-response path. Developers report big wins in:
Generating complete front-end layouts with proper spacing, typography, accessibility, and responsive breakpoints.
Debugging large repositories with coherent navigation between modules and tests.
One-prompt app scaffolding, delivering functional starter apps with routing, data fetching, and state management.
GPT-5 Pro extends the lead, with fewer subtle logic errors, more resilient refactors, and better adherence to strict style guides. o3 remains competent in algorithmic reasoning, and GPT-4o still offers stable multimodal support, but the day-to-day developer experience feels faster and more accurate on GPT-5.
Tip: Turn on tool usage (Python, sandbox, or your IDE connector) and allow the model to run tests. The pass rate jumps when it can execute and verify code.
DevOps & infra: Terraform/IaC stubs, Dockerfiles, GitHub Actions, schema migrations, solid out of the box, better with a short style brief.
Security awareness: Proactively suggests input validation, dependency pinning, and basic threat models during code review.
Bottom line: If your day involves multi-language work, GPT-5 cuts context-switching overhead. For mission-critical code reviews and large-scale refactors, GPT-5 Pro remains the top pick.
Olympiad (AIME/USAMO) and contest-style reasoning are longstanding AI yardsticks. With Python enabled, GPT-5 Pro is exceptional at multi-step algebraic manipulation, geometry with numeric verification, and combinatorics. GPT-5 (Thinking) often lands just behind Pro while dramatically beating non-thinking baselines. o3 remains a competitive legacy option for pure math tasks; GPT-4o lags on the hardest problems but still performs well for general math help and explanations.
When to enable tools: If a problem involves multiple numeric checks, symbolic manipulation, or verifying a case split, let the model run Python. Error rates drop and explanations improve.
Agentic Capabilities & Tool Integration
Browse & Research (Agent)
ChatGPT Agent builds on GPT-5 to search, browse, and synthesize information across multiple sources. It’s best for:
Market & competitive intelligence (triangulating data across analyst notes, filings, and news).
Literature reviews (exportable summaries and citation lists).
Ops automation (retrieving docs from Drive/SharePoint, updating sheets, sending messages in Slack/Teams).
Why it’s better now: The agent is more reliable at following multi-turn instructions, keeping context across steps, and resolving tool errors (e.g., authentication, malformed inputs) without derailing the task.
Function Calling & Business Workflows
In structured tool-calling (bookings, orders, troubleshooting), GPT-5 (Thinking) coordinates multiple functions with higher accuracy than prior models. Common high-ROI patterns include:
Retail/CPG: Cart builds, promotions/eligibility checks, order edits, returns & refunds.
Telecom/Utilities: Diagnostics, guided troubleshooting, ticket creation, and follow-ups.
Deep Research Connectors & Model Context Protocol (MCP)
Deep Research connectors (Google Drive, SharePoint, Dropbox, GitHub, HubSpot, and custom MCP connectors) let GPT-5 pull from multiple sources, reconcile conflicts, and produce coherent reports with citations. This is especially useful for analysts and researchers working with fragmented data.
Multimodal Reasoning (Vision, Audio, Video)
GPT-5 improves vision and audiovisual understanding:
Charts & documents: Better at extracting structured data, reconciling units, and sanity-checking figures.
Screenshots & UI states: Reliable at diagnosing UI bugs and suggesting reproducible steps.
Audio & video: Transcription, translation, and summarization quality see incremental gains with less latency.
MMMU & ARC-style tasks show GPT-5 (Thinking) outperforming GPT-4o and o3 on college-level multimodal questions. If your workflow blends text + visuals (reports, product docs, A/B test readouts), GPT-5 is easier to trust.
Processing Power, Efficiency & Token Economics
Context & Output Efficiency
GPT-5 dynamically allocates compute and tends to use fewer output tokens than o3 for the same task while maintaining or improving accuracy. For simple prompts, you’ll get short, on-point answers; for complex ones, you’ll see longer, structured reasoning.
Practical impact:
Faster responses to routine tasks.
Lower cost per solved task at the same, or better, quality.
Better UX with less fluff and more verifiable steps when the problem is hard.
Team workflows: If several teammates rely on complex runs daily, Pro’s consistency pays for itself.
Pricing, Plans & API Costs (2025)
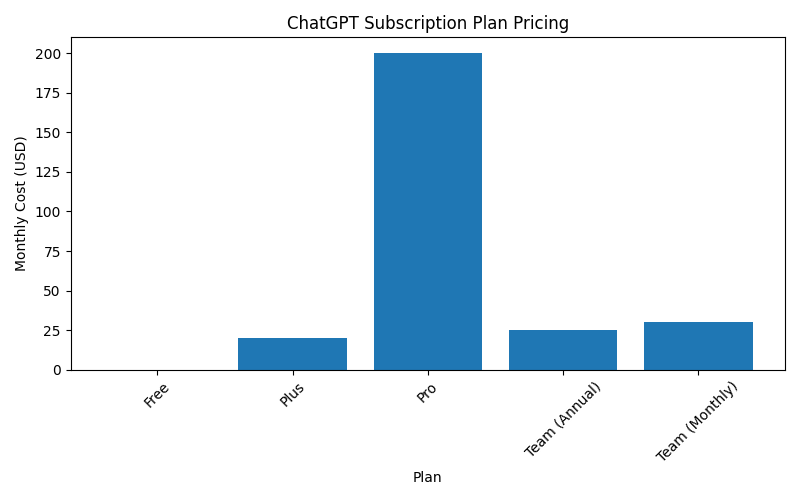
Free: $0/mo; GPT-5 until limits are reached, then automatic fallback to mini. No guaranteed access to Pro/Agent features.
Plus: ~$20/mo; significantly higher limits than Free; access to Agent and research connectors on a metered basis.
Pro: ~$200/mo; unlimited access to GPT-5 family (subject to abuse guardrails), including GPT-5 Pro and Agent features.
Team: ~$25/user/mo; team management, sharing, and generous limits; Pro-class features available.
Enterprise/Edu: Custom pricing, widest controls, and governance.
API pricing: GPT-5 flagship is priced for input and output tokens separately; mini and nano tiers are notably cheaper for high-volume or latency-sensitive applications. (Consult the latest pricing page for the exact rates.)
Tip: Many organizations mix tiers—use GPT-5 Pro for high-stakes or agentic flows and mini/nano for bulk classification, extraction, and templated replies.
ROI Analysis for GPT-5 Pro (Illustrative)
Consider a developer who completes ~200 complex tasks/month (bugfixes, refactors, test authoring):
Time saved: ~12 minutes/task on average when using GPT-5 Pro’s deeper reasoning, unit-test generation, and inline refactors → ~40 hours/month.
Value: At a blended cost of $50/hour, that’s $2,000/month in recovered time.
Cost:$200/month for Pro → ~10× ROI before factoring quality gains (fewer regressions, quicker reviews) and reduced context switching.
Similar math often holds for analysts (data synthesis, slide builds), support teams (automated resolutions), and product managers (briefs, experiments, market scans).
Strengths & Weaknesses by Model (2025)
Model
Strengths
Limitations
GPT-5 (Standard)
Unified intelligence; excellent default for coding, writing, and analysis; automatic tool use; strong multimodal support
Daily caps on Free; Thinking Mode may be truncated on very long chains; fewer admin controls than Team/Enterprise
GPT-5 Pro
Peak accuracy and consistency; extended internal reasoning; superior instruction following; lowest major-error rate
Higher cost; slightly longer latency on deep runs; overkill for simple asks
ChatGPT Agent
Orchestrates multi-tool workflows; improves browse/research; reliable function-calling for line-of-business tasks
Requires setup (auth, scopes, data governance); works best with well-scoped prompts and guardrails; supervision still advised
GPT-4o & o3 (Legacy)
Stable baselines, broad API availability, and a large ecosystem of examples
Lower peak performance on hard reasoning; weaker multimodal consistency vs GPT-5; some features deprecated in the web UI
Decision Framework: Which Model Should You Use?
Daily use & general questions → GPT-5 (Standard) Students, creators, and knowledge workers get great value from the default model. Upgrade to Plus for higher limits and Agent access.
Software engineering & complex problem-solving → GPT-5 Pro Professional developers and engineering teams benefit from Pro’s extended reasoning and instruction following—best for architecture work, complex debugging, performance tuning, and rigorous code reviews.
Business process automation → ChatGPT Agent Ops, CX, and analytics teams can automate workflows—customer service, back-office tasks, data reconciliation—with well-scoped tools and connectors.
Academic & market research → Deep Research Connectors Use ChatGPT with Drive/SharePoint/GitHub connectors for literature reviews, competitive intel, and data synthesis. Plus is fine for light reviews; Pro/Team scales for heavy use.
Safety, Accuracy & Reliability
Reduced Hallucinations & Better Factuality
GPT-5 substantially reduces factuality errors compared with legacy models, especially in Thinking Mode, where it cross-checks intermediate results and cites sources more consistently. In production, users report fewer “confidently wrong” answers and better self-corrections.
Deception & Honesty Metrics
Compared to earlier models (notably some o-series variants), GPT-5 shows lower false confidence and more willingness to say “I don’t know.” This reduces risk in regulated contexts and expert workflows.
On general health queries and harder clinical vignettes, GPT-5 outperforms GPT-4o and o3 but remains non-diagnostic. It’s a helpful assistant for education, triage questions, and documentation, but not a substitute for medical professionals.
Tip: Governance reminder: Keep proper human-in-the-loop, source logging, and change-management for any safety-critical deployment.
Practical Setup Tips (Teams & Enterprises)
Choose the right tier mix: Map tasks to models, Pro for high-stakes reasoning; mini/nano for repetitive/templated tasks.
Enable connectors: Wire up Drive/SharePoint/GitHub; define scopes and retention policies.
Create instruction briefs: Provide compact style guides and checklist prompts for repeatable outputs (PRD templates, code review rubrics, research notes).
Sandboxed tools: Allow Python or internal tools where safe; add guardrails (rate limits, validation) around function calls.
Measure outcomes: Track task completion time, defect rates, and review cycles to quantify ROI and tune prompts.
Conclusion
GPT-5 redefines default AI behavior. The router chooses the right level of effort automatically, while Thinking Mode, improved multimodal understanding, better tool use, and a safer reasoning stack meaningfully raise the bar.
Individuals can start free and upgrade as needs grow; teams should consider Plus/Team for collaboration and Pro where accuracy and deep reasoning matter most.
Looking forward, expect tighter agent frameworks, richer connectors, and continued gains in safety and planning. The trajectory is clear: models adapt to us, not the other way around.
FAQs
What’s the difference between GPT-5 and GPT-5 Pro?
GPT-5 Pro runs longer, deeper reasoning with higher instruction fidelity and lower error rates. GPT-5 (Standard) automatically thinks when needed but keeps a tighter budget for speed and cost.
Should I switch from GPT-4o or o3?
If you care about hard reasoning, coding depth, and multimodal consistency, yes. GPT-5 beats both on most demanding tasks while being more efficient.
Does GPT-5 really reduce hallucinations?
Yes, especially in Thinking Mode with tools enabled. You’ll see more guarded claims, requests for clarification, and better citations in research flows.
Is Pro worth $200/month?
For professionals who run complex tasks daily, the time saved and error reduction typically pay for the plan several times over. For light use, Plus or Free may suffice.
What about privacy and compliance?
Use Team/Enterprise for org policies, audit logs, and data controls. Configure data retention and connector scopes per your compliance regime.